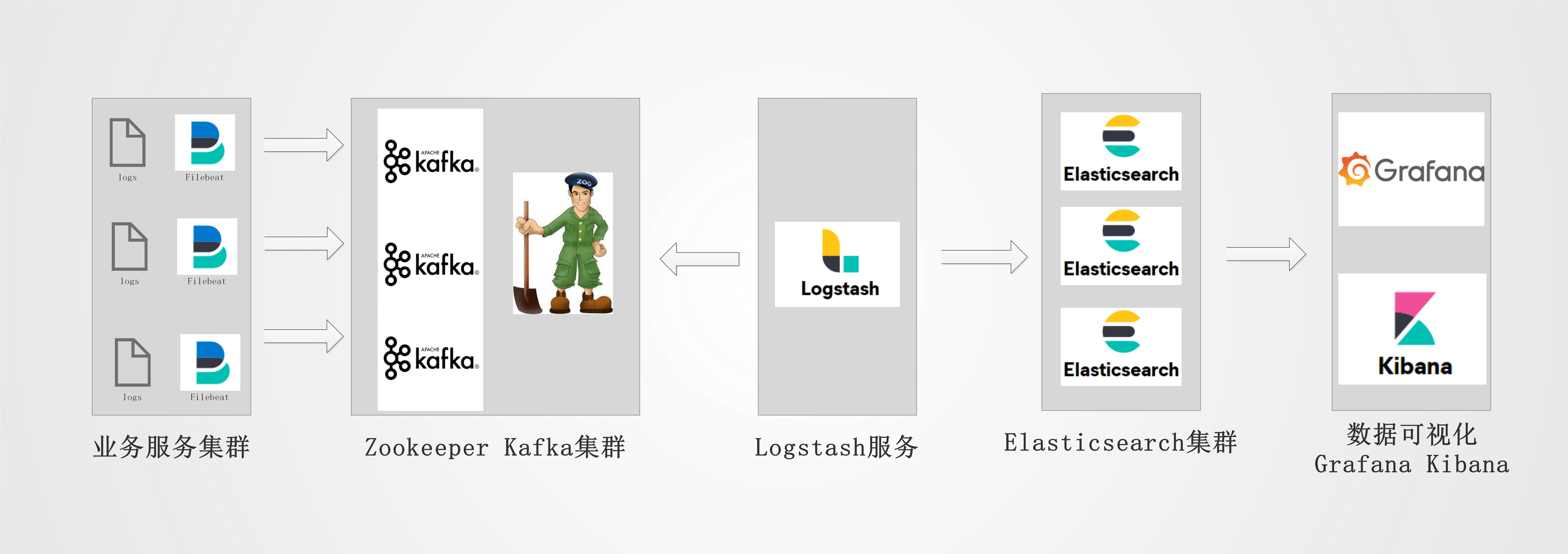
ELK+kafka+filebeat搭建生产ELFK集群
ELK 架构介绍
集群服务版本
服务
版本
java
1.8.0_221
elasticsearch
7.10.1
filebeat
7.10.1
kibana
7.10.1
logstash
7.10.1
cerebro
0.9.2-1
kafka
2.12-2.3.0
zookeeper
3.5.6
服务器环境说明
IP地址
主机名
配置
角色
10.0.11.172
elk-master
4C16G
es-master、kafka+zookeeper1
10.0.21.117
elk-node1
4C16G
es-node1、kafka+zookeeper2
10.0.11.208
elk-node2
4C16G
es-node2、kafka+zookeeper3
10.0.10.242
elk-kibana
4C16G
logstash、kibana、cerebro
系统参数优化
三个节点都需要执行
修改主机名
1
2
3
hostnamectl set-hostname elk-master
hostnamectl set-hostname elk-node1
hostnamectl set-hostname elk-node2
增加文件描述符
1
2
3
4
5
6
7
8
cat >>/etc/security/limits.conf<< EOF
* soft nofile 65536
* hard nofile 65536
* soft nproc 65536
* hard nproc 65536
* hard memlock unlimited
* soft memlock unlimited
EOF
修改默认限制内存
1
2
3
4
5
cat >>/etc/systemd/system.conf<< EOF
DefaultLimitNOFILE=65536
DefaultLimitNPROC=32000
DefaultLimitMEMLOCK=infinity
EOF
优化内核,对es支持
1
2
3
4
5
6
7
8
9
10
11
12
cat >>/etc/sysctl.conf<< EOF
# 关闭交换内存
vm.swappiness =0
# 影响java线程数量,建议修改为262144或者更高
vm.max_map_count= 262144
# 优化内核listen连接
net.core.somaxconn=65535
# 最大打开文件描述符数,建议修改为655360或者更高
fs.file-max=655360
# 开启ipv4转发
net.ipv4.ip_forward= 1
EOF
修改Hostname配置文件
1
2
3
4
5
cat >>/etc/hosts<< EOF
elk-master 10.0.11.172
elk-node1 10.0.21.117
elk-node2 10.0.11.208
EOF
重启使配置生效
部署Zookeeper
三个节点都需要执行
创建Zookeeper项目目录
1
2
3
4
#存放快照日志
mkdir zkdata
#存放事物日志
mkdir zklogs
下载解压zookeeper
1
2
3
wget http://mirror.bit.edu.cn/apache/zookeeper/zookeeper-3.5.6/apache-zookeeper-3.5.6-bin.tar.gz
tar -zxvf apache-zookeeper-3.5.6-bin.tar.gz
mv apache-zookeeper-3.5.6-bin zookeeper
修改配置文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
[ root@elk-master zookeeper] # cat conf/zoo.cfg |grep -v ^#
# 服务器之间或客户端与服务器之间维持心跳的时间间隔
# tickTime以毫秒为单位。
tickTime = 2000
# 集群中的follower服务器(F)与leader服务器(L)之间的初始连接心跳数
initLimit = 10
# 集群中的follower服务器与leader服务器之间请求和应答之间能容忍的最多心跳数
syncLimit = 5
# 数据保存目录
dataDir = ../zkdata
# 日志保存目录
dataLogDir = ../zklogs
# 客户端连接端口
clientPort = 2181
# 客户端最大连接数。# 根据自己实际情况设置,默认为60个
maxClientCnxns = 60
# 三个接点配置,格式为: server.服务编号=服务地址、LF通信端口、选举端口
server.1= 10.0.11.172:2888:3888
server.2= 10.0.21.117:2888:3888
server.3= 10.0.11.208:2888:3888
写入节点标记
分别在三个节点/home/tools/zookeeper/zkdata/myid写入节点标记
master节点
node1节点
node2节点
master的操作
1
echo "1" > /home/tools/zookeeper/zkdata/myid
node1的操作
1
echo "2" > /home/tools/zookeeper/zkdata/myid
node2的操作
1
echo "3" > /home/tools/zookeeper/zkdata/myid
启动zookeeper集群
1
2
3
4
5
[ root@elk-master zookeeper] # cd /home/tools/zookeeper/bin/
[ root@elk-master bin] # ./zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /home/tools/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
检查集群状态
1
2
3
4
5
[ root@elk-master bin] # sh /home/tools/zookeeper/bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /home/tools/zookeeper/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost.
Mode: leader
设置全局变量
1
2
3
4
5
cat >>/etc/profile<< EOF
export ZOOKEEPER_INSTALL=/home/tools/zookeeper/
export PATH=$PATH:$ZOOKEEPER_INSTALL/bin
export PATH
EOF
这样就可以全局使用zkServer.sh命令了
部署 Kafka
三个节点都需要执行
下载解压kafka压缩包
1
2
3
4
5
6
[ root@elk-master tools] # mkdir kafka
[ root@elk-master tools] # cd kafka/
[ root@elk-master kafka] # wget https://www-eu.apache.org/dist/kafka/2.3.0/kafka_2.12-2.3.0.tgz
[ root@elk-master kafka] # tar xf kafka_2.12-2.3.0.tgz
[ root@elk-master kafka] # mv kafka_2.12-2.3.0 kafka
[ root@elk-master kafka] # cd kafka/config/
配置kafka
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
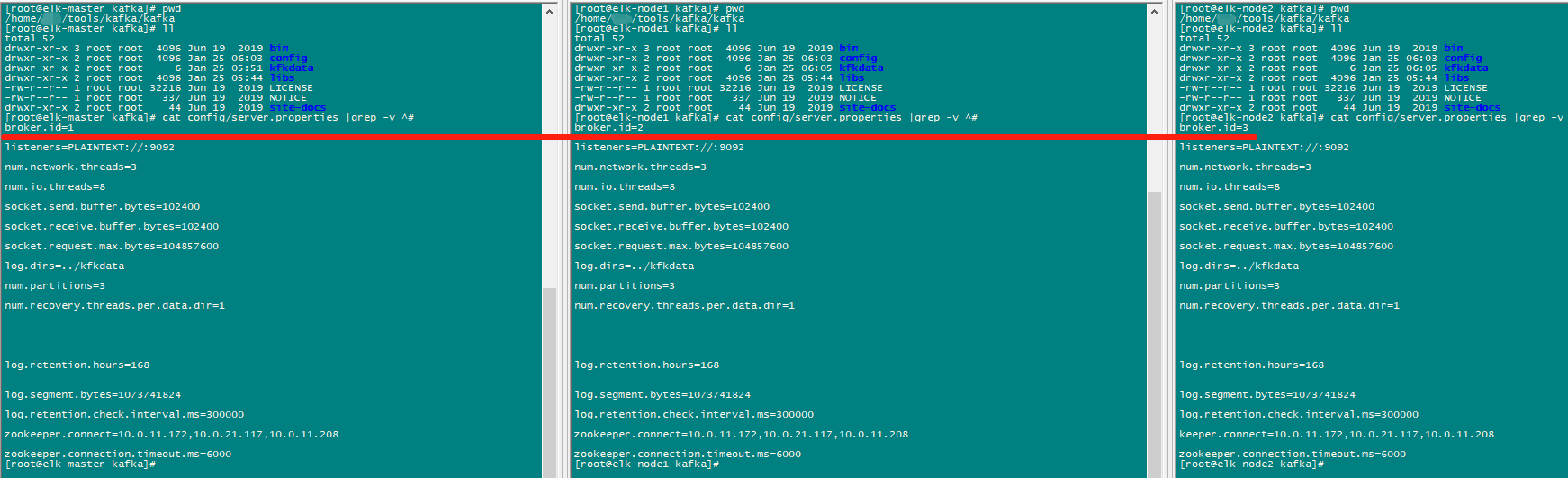
[ root@elk-master config] # cat /home/tools/kafka/kafka/config/server.properties
############################# Server Basics #############################
# broker的id,值为整数,且必须唯一,在一个集群中不能重复
broker.id= 1
############################# Socket Server Se:ttings #############################
# kafka默认监听的端口为9092 (默认与主机名进行连接)
listeners = PLAINTEXT://:9092
# 处理网络请求的线程数量,默认为3个
num.network.threads= 3
# 执行磁盘IO操作的线程数量,默认为8个
num.io.threads= 8
# socket服务发送数据的缓冲区大小,默认100KB
socket.send.buffer.bytes= 102400
# socket服务接受数据的缓冲区大小,默认100KB
socket.receive.buffer.bytes= 102400
# socket服务所能接受的一个请求的最大大小,默认为100M
socket.request.max.bytes= 104857600
############################# Log Basics #############################
# kafka存储消息数据的目录
log.dirs= ../kfkdata
# 每个topic默认的partition数量
num.partitions= 3
# 在启动时恢复数据和关闭时刷新数据时每个数据目录的线程数量
num.recovery.threads.per.data.dir= 1
############################# Log Flush Policy #############################
# 消息刷新到磁盘中的消息条数阈值
#log.flush.interval.messages=10000
# 消息刷新到磁盘中的最大时间间隔,1s
#log.flush.interval.ms=1000
############################# Log Retention Policy #############################
# 日志保留小时数,超时会自动删除,默认为7天
log.retention.hours= 168
# 日志保留大小,超出大小会自动删除,默认为1G
#log.retention.bytes=1073741824
# 日志分片策略,单个日志文件的大小最大为1G,超出后则创建一个新的日志文件
log.segment.bytes= 1073741824
# 每隔多长时间检测数据是否达到删除条件,300s
log.retention.check.interval.ms= 300000
############################# Zookeeper #############################
# Zookeeper连接信息,如果是zookeeper集群,则以逗号隔开
zookeeper.connect= 10.0.11.172,10.0.21.117,10.0.11.208
# 连接zookeeper的超时时间,6s
zookeeper.connection.timeout.ms= 6000
创建数据存储的目录
1
[ root@elk-master config] # mkdir ../kfkdata
修改broker.id
分别在三个节点依次修改/home/tools/kafka/kafka/config/server.properties配置文件
启动kafka集群
1
2
3
4
5
cd /home/tools/kafka/kafka/bin/
#启动测试
./kafka-server-start.sh ../config/server.properties
#放入后台
./kafka-server-start.sh -daemon ../config/server.properties
测试
任意节点均可执行
创建topic
消息发布
topic消息订阅
1
2
3
4
5
6
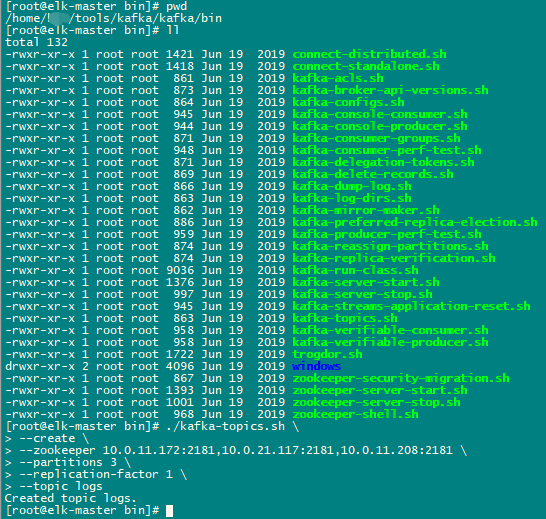
[ root@elk-master bin] # ./kafka-topics.sh \
--create \
\
3 \
1 \
1
2
3
[ root@elk-master bin] # ./kafka-console-producer.sh \
--broker-list 10.0.11.172:9092,10.0.21.117:9092,10.0.11.208:9092 \
1
2
3
4
[ root@elk-master bin] # ./kafka-console-consumer.sh \
--bootstrap-server 10.0.11.172:9092,10.0.21.117:9092,10.0.11.208:9092 \
\
部署elasticsearch
三个节点都需要执行
下载安装elasticsearch
1
2
wget https://pan.cnsre.cn/d/Package/Linux/ELK/elasticsearch-7.10.1-x86_64.rpm
[ root@elk-master package] # rpm -ivh elasticsearch-7.10.1-x86_64.rpm
备份配置文件
1
2
cd /etc/elasticsearch
cp elasticsearch.yml elasticsearch.yml.bak
修改配置文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
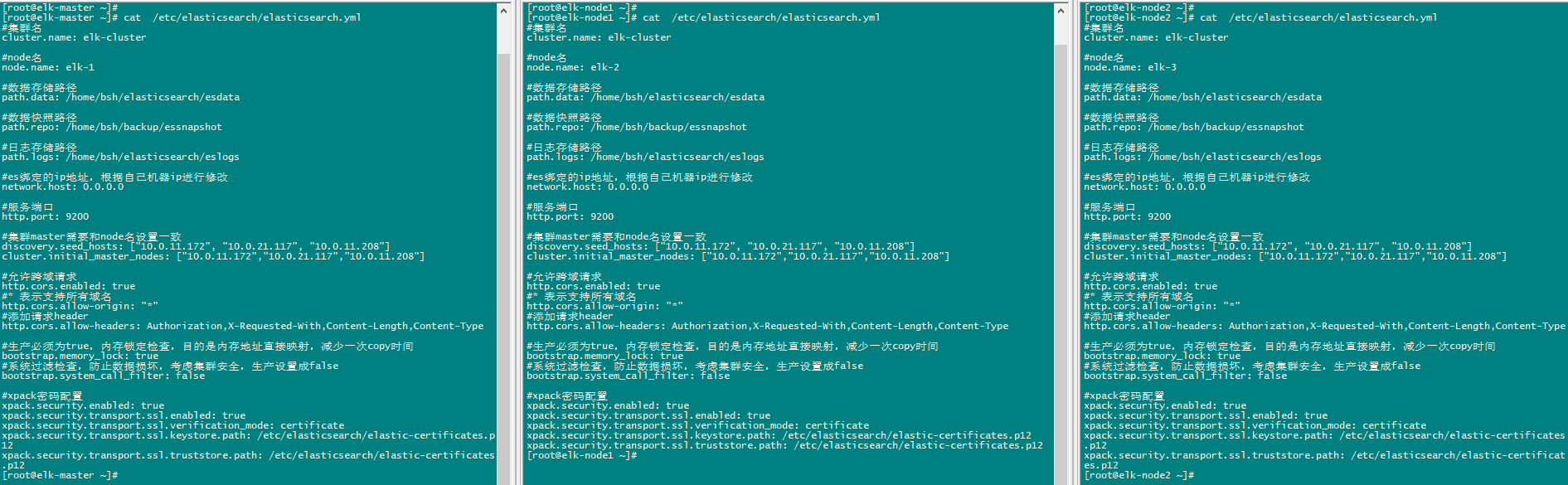
cat >/etc/elasticsearch/elasticsearch.yml << EOF
#集群名
cluster.name: elk-cluster
#node名
node.name: elk-1
#数据存储路径
path.data: /home/elasticsearch/esdata
#数据快照路径
path.repo: /home/backup/essnapshot
#日志存储路径
path.logs: /home/elasticsearch/eslogs
#es绑定的ip地址,根据自己机器ip进行修改
network.host: 0.0.0.0
#服务端口
http.port: 9200
#集群master需要和node名设置一致
discovery.seed_hosts: ["10.0.11.172", "10.0.21.117", "10.0.11.208"]
cluster.initial_master_nodes: ["10.0.11.172","10.0.21.117","10.0.11.208"]
#允许跨域请求
http.cors.enabled: true
#* 表示支持所有域名
http.cors.allow-origin: "*"
#添加请求header
http.cors.allow-headers: Authorization,X-Requested-With,Content-Length,Content-Type
#生产必须为true,内存锁定检查,目的是内存地址直接映射,减少一次copy时间
bootstrap.memory_lock: true
#系统过滤检查,防止数据损坏,考虑集群安全,生产设置成false
bootstrap.system_call_filter: false
#xpack配置
xpack.security.enabled: true
xpack.security.transport.ssl.enabled: true
xpack.security.transport.ssl.verification_mode: certificate
xpack.security.transport.ssl.keystore.path: /etc/elasticsearch/elastic-certificates.p12
xpack.security.transport.ssl.truststore.path: /etc/elasticsearch/elastic-certificates.p12
EOF
修改JVM
将jvm.options文件中22-23行的8g设置为你的服务内存的一半
1
2
3
[ root@elk-node1 elasticsearch] # cat -n jvm.options |grep 8g
22 -Xms8g
23 -Xmx8g
修改其他节点配置
分别在三个节点修改/etc/elasticsearch/elasticsearch.yml配置文件
分配权限
因为自定义数据、日志存储目录,所以要把权限给到目录
1
2
3
4
mkdir -p /home/elasticsearch/{ esdata,eslogs}
chown elasticsearch:elasticsearch /home/elasticsearch/*
mkdir -p /home/backup/essnapshot
chown elasticsearch:elasticsearch /home/backup/essnapshot
启动服务
三个节点全部启动并加入开机启动
1
2
systemctl start elasticsearch
systemctl enable elasticsearch
使用xpack进行安全认证
xpack的安全功能
1
2
3
4
5
6
7
8
9
10
Unexpected response code [ 503] from calling PUT http://10.0.11.172:9200/_security/user/apm_system/_password?pretty
Cause: Cluster state has not been recovered yet, cannot write to the [ null] index
Possible next steps:
* Try running this tool again.
* Try running with the --verbose parameter for additional messages.
* Check the elasticsearch logs for additional error details.
* Use the change password API manually.
ERROR: Failed to set password for user [ apm_system] .
申请证书
下面的操作,在其中一个节点操作即可
1
2
/usr/share/elasticsearch/bin/elasticsearch-certutil ca
/usr/share/elasticsearch/bin/elasticsearch-certutil cert --ca elastic-stack-ca.p12
两条命令均一路回车即可,不需要给秘钥再添加密码
[root@elk-master ~]# ls /usr/share/elasticsearch/elastic-*
/usr/share/elasticsearch/elastic-certificates.p12
/usr/share/elasticsearch/elastic-stack-ca.p12
cp /usr/share/elasticsearch/elastic-* /etc/elasticsearch/
chown elasticsearch.elasticsearch /etc/elasticsearch/elastic*
做完之后,将证书拷贝到其他节点
为内置账号添加密码
ES中内置了几个管理其他集成组件的账号apm_system, beats_system, elastic, kibana, logstash_system, remote_monitoring_user使用之前,首先需要设置下密码。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
/usr/share/elasticsearch/bin/elasticsearch-setup-passwords interactive
Initiating the setup of passwords for reserved users elastic,apm_system,kibana,logstash_system,beats_system,remote_monitoring_user.
You will be prompted to enter passwords as the process progresses.
Please confirm that you would like to continue [ y/N] y
Enter password for [ elastic] :
Reenter password for [ elastic] :
Enter password for [ apm_system] :
Reenter password for [ apm_system] :
Enter password for [ kibana] :
Reenter password for [ kibana] :
Enter password for [ logstash_system] :
Reenter password for [ logstash_system] :
Enter password for [ beats_system] :
Reenter password for [ beats_system] :
Enter password for [ remote_monitoring_user] :
Reenter password for [ remote_monitoring_user] :
Changed password for user [ apm_system]
Changed password for user [ kibana]
Changed password for user [ logstash_system]
Changed password for user [ beats_system]
Changed password for user [ remote_monitoring_user]
Changed password for user [ elastic]
部署 Cerebro
下载安装
1
2
wget https://pan.cnsre.cn/d/Package/Linux/ELK/cerebro-0.9.2-1.noarch.rpm
rpm -ivh cerebro-0.9.2-1.noarch.rpm
修改配置文件
修改/etc/cerebro/application.conf配置文件
修改内容一
修改内容二
1
2
data.path: "/var/lib/cerebro/cerebro.db"
#data.path = "./cerebro.db"
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
hosts = [
#{
# host = "http://localhost:9200"
# name = "Localhost cluster"
# headers-whitelist = [ "x-proxy-user", "x-proxy-roles", "X-Forwarded-For" ]
#}
# Example of host with authentication
{
host = "http://10.0.11.172:9200"
name = "elk-cluster"
auth = {
username = "elastic"
password = "123"
}
}
]
报错
cerebro[8073]: No java installations was detected.
No java,但是我的环境是有JAVA的。也做了全局变量解决方法
在启动服务文件中加入JAVA_HOME
找到服务启动文件/usr/share/cerebro/bin/cerebro
修改/usr/share/cerebro/bin/cerebro中的JAVA_HOMEJAVA_HOME填写路径
修改前
修改后
1
2
3
4
5
6
7
if [[ -n " $bundled_jvm " ]] ; then
echo " $bundled_jvm /bin/java"
elif [[ -n " $JAVA_HOME " ]] && [[ -x " $JAVA_HOME /bin/java" ]] ; then
echo " $JAVA_HOME /bin/java"
else
echo "java"
fi
1
2
3
4
5
6
7
if [[ -n " $bundled_jvm " ]] ; then
echo " $bundled_jvm /bin/java"
elif [[ -n "/home/tools/jdk1.8.0_221" ]] && [[ -x "/home/tools/jdk1.8.0_221/bin/java" ]] ; then
echo "/home/tools/jdk1.8.0_221/bin/java"
else
echo "java"
fi
启动服务
1
2
3
systemctl start cerebro.service
systemctl enable cerebro.service
systemctl status cerebro.service
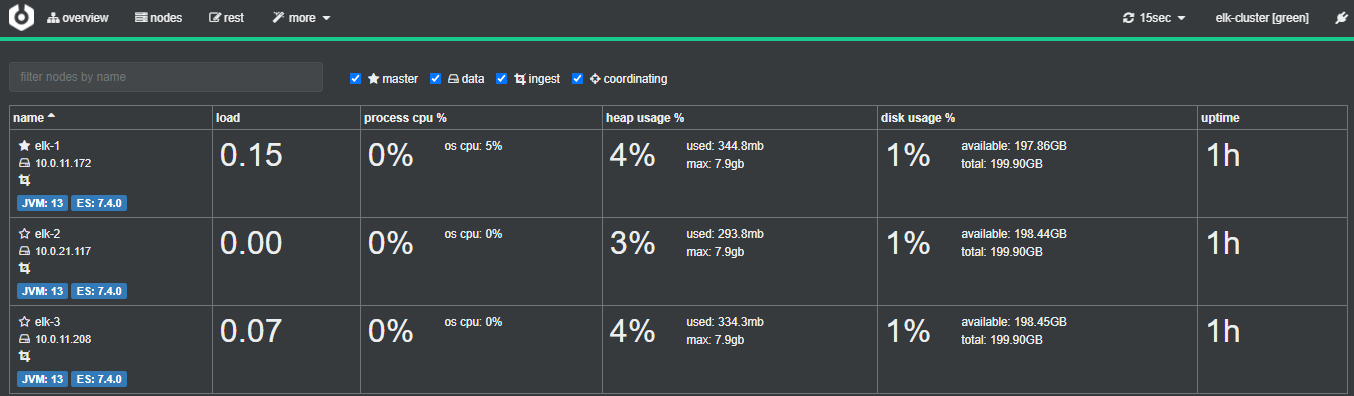
可以看到监听的是9000端口
部署Kibana
下载安装
1
2
https://artifacts.elastic.co/downloads/kibana/kibana-7.10.1-x86_64.rpm
rpm -ivh kibana-7.10.1-x86_64.rpm
修改备份配置文件
1
2
cd /etc/kibana/
mv kibana.yml kibana.yml.bak
1
2
3
4
5
6
7
vim kibana.yml
server.port: 5601
server.host: 0.0.0.0
elasticsearch.hosts: [ "http://10.0.11.172:9200/" ,"http://10.0.21.117:9200/" ,"http://10.0.11.208:9200/" ]
elasticsearch.username: "elastic"
elasticsearch.password: "123"
i18n.locale: "zh-CN"
启动服务器
1
2
3
systemctl start kibana.service
systemctl enable kibana.service
systemctl status kibana.service
访问WEB
访问http://IP:5601
部署filebeat
1
2
3
4
wget https://pan.cnsre.cn/d/Package/Linux/ELK/filebeat-7.10.1-x86_64.rpm
rpm -ivh filebeat-7.10.1-x86_64.rpm
cd /etc/filebeat/
cp filebeat.yml filebeat.yml.bak
修改配置文件
修改filebeat配置文件,把日志推送到kafka
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
#=========================== Filebeat inputs =============================
max_procs : 1 #限制filebeat的进程数量,其实就是内核数,避免过多抢占业务资源
queue.mem.events : 256 # 存储于内存队列的事件数,排队发送 (默认4096)
queue.mem.flush.min_events : 128 # 小于 queue.mem.events ,增加此值可提高吞吐量 (默认值2048)
filebeat.inputs : # inputs为复数,表名type可以有多个
type : log # 输入类型
enable : true # 启用这个type配置
paths :
- /home/homeconnect/logs/AspectLog/aspect.log # 监控tomcat 的业务日志
json.keys_under_root : true #默认Flase,还会将json解析的日志存储至messages字段
json.overwrite_keys : true #覆盖默认的key,使用自定义json格式的key
max_bytes : 20480 # 单条日志的大小限制,建议限制(默认为10M,queue.mem.events * max_bytes 将是占有内存的一部)
fields : # 额外的字段
source : test-prod-tomcat-aspect-a # 自定义source字段,用于es建议索引(字段名小写,我记得大写好像不行)
type : log # 输入类型
enable : true # 启用这个type配置
paths :
- /home/tools/apache-tomcat-8.5.23/logs/localhost_access_log.*.log # 监控tomcat access日志
json.keys_under_root : true #默认Flase,还会将json解析的日志存储至messages字段
json.overwrite_keys : true #覆盖默认的key,使用自定义json格式的key
max_bytes : 20480 # 单条日志的大小限制,建议限制(默认为10M,queue.mem.events * max_bytes 将是占有内存的一部分)
fields : # 额外的字段
source : test-prod-tomcat-access-a # 自定义source字段,用于es建议索引
# 自定义es的索引需要把ilm设置为false
setup.ilm.enabled : false
#=============================== output ===============================
output.kafka : # 输出到kafka
enabled : true # 该output配置是否启用
hosts : [ "10.0.11.172:9092" , "10.0.21.117:9092" , "10.0.11.208:9092" ] # kafka节点列表
topic : 'logstash-%{[fields.source]}' # kafka会创建该topic,然后logstash(可以过滤修改)会传给es作为索引名称
partition.hash :
reachable_only : true # 是否只发往可达分区
compression : gzip # 压缩
max_message_bytes : 1000000 # Event最大字节数。默认1000000。应小于等于kafka broker message.max.bytes值
required_acks : 1 # kafka ack等级
worker : 1 # kafka output的最大并发数
bulk_max_size : 2048 # 单次发往kafka的最大事件数
logging.to_files : true # 输出所有日志到file,默认true, 达到日志文件大小限制时,日志文件会自动限制替换
#=============================== other ===============================
close_older : 30m # 如果文件在某个时间段内没有发生过更新,则关闭监控的文件handle。默认1h
force_close_files : false # 这个选项关闭一个文件,当文件名称的变化。只在window建议为true
# 没有新日志采集后多长时间关闭文件句柄,默认5分钟,设置成1分钟,加快文件句柄关闭
close_inactive : 1m
# 传输了3h后荏没有传输完成的话就强行关闭文件句柄,这个配置项是解决以上案例问题的key point
close_timeout : 3h
# 这个配置项也应该配置上,默认值是0表示不清理,不清理的意思是采集过的文件描述在registry文件里永不清理,在运行一段时间后,registry会变大,可能会带来问题
clean_inactive : 72h
# 设置了clean_inactive后就需要设置ignore_older,且要保证ignore_older < clean_inactive
ignore_older : 70h
启动服务
1
2
3
systemctl start filebeat.service
systemctl enable filebeat.service
systemctl status filebeat.service
部署logstash
下载安装
1
2
3
wget https://pan.cnsre.cn/d/Package/Linux/ELK/logstash-7.10.1-x86_64.rpm
rpm -ivh logstash-7.10.1-x86_64.rpm
mv logstash.yml logstash.yml.bak
修改配置文件
修改logstash.yml
1
2
3
4
5
6
vim logstash.yml
http.host : "0.0.0.0"
# 指发送到Elasticsearch的批量请求的大小,值越大,处理则通常更高效,但增加了内存开销
pipeline.batch.size : 3000
# 指调整Logstash管道的延迟,过了该时间则logstash开始执行过滤器和输出
pipeline.batch.delay : 200
修改配置文件,从kafka获取日志
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
[ root@elk-kibana conf.d] # cat /etc/logstash/conf.d/get-kafka-logs.conf
input { # 输入组件
kafka { # 从kafka消费数据
bootstrap_servers = > [ "10.0.11.172:9092,10.0.21.117:9092,10.0.11.208:9092" ]
codec = > "json" # 数据格式
#topics => ["3in1-topi"] # 使用kafka传过来的topic
topics_pattern = > "logstash-.*" # 使用正则匹配topic
consumer_threads = > 3 # 消费线程数量
decorate_events = > true # 可向事件添加Kafka元数据,比如主题、消息大小的选项,这将向logstash事件中添加一个名为kafka的字段
auto_offset_reset = > "latest" # 自动重置偏移量到最新的偏移量
#group_id => "logstash-node" # 消费组ID,多个有相同group_id的logstash实例为一个消费组
#client_id => "logstash1" # 客户端ID
fetch_max_wait_ms = > "1000" # 指当没有足够的数据立即满足fetch_min_bytes时,服务器在回答fetch请求之前将阻塞的最长时间
}
}
filter{
# 当非业务字段时,无traceId则移除
#if ([message] =~ "traceId=null") { # 过滤组件,这里只是展示,无实际意义,根据自己的业务需求进行过滤
# drop {}
#}
mutate {
convert = > [ "Request time" , "float" ]
}
if [ ip] != "-" {
geoip {
source = > "ip"
target = > "geoip"
# database => "/usr/share/GeoIP/GeoIPCity.dat"
add_field = > [ "[geoip][coordinates]" , "%{[geoip][longitude]}" ]
add_field = > [ "[geoip][coordinates]" , "%{[geoip][latitude]}" ]
}
mutate {
convert = > [ "[geoip][coordinates]" , "float" ]
}
}
}
output { # 输出组件
elasticsearch { # Logstash输出到es
hosts = > [ "10.0.11.172:9200" ,"10.0.21.117:9200" ,"10.0.11.208:9200" ]
index = > "logstash-%{[fields][source]}-%{+YYYY-MM-dd}" # 直接在日志中匹配
#index => "%{[@metadata][topic]}-%{+YYYY-MM-dd}" # 以日期建索引
user = > "elastic"
password = > "123"
}
#stdout {
# codec => rubydebug
#}
}
测试接收日志
测试是否能接收到数据
1
/usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/get-kafka-logs.conf
下边把logstash设置为使用systemd启动/etc/systemd/system/logstash.service文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
[ Unit]
Description = root
[ Service]
Type = simple
User = root
Group = root
# Load env vars from /etc/default/ and /etc/sysconfig/ if they exist.
# Prefixing the path with '-' makes it try to load, but if the file doesn't
# exist, it continues onward.
EnvironmentFile = -/etc/default/logstash
EnvironmentFile = -/etc/sysconfig/logstash
ExecStart = /usr/share/logstash/bin/logstash "--path.settings" "/etc/logstash"
Restart = alway
WorkingDirectort = /
Nice = 19
LimitNOFILE = 16384
[ Install]
WantedBy = multi-user.target
在启动程序/usr/share/logstash/bin/logstash.lib.sh中加入JAVA_HOMEif [ -z "$JAVACMD" ]; then代码上方插入一行JAVACMD="/home/tools/jdk1.8.0_221/bin/java" 具体的路径需要你根据自己的JAVA来修改。
1
2
3
4
[ root@elk-kibana ~] # cat -n /usr/share/logstash/bin/logstash.lib.sh |grep JAVACMD
85 # set the path to java into JAVACMD which will be picked up by JRuby to launch itself
86 JAVACMD = "/home/tools/jdk1.8.0_221/bin/java"
87 if [ -z " $JAVACMD " ] ; then
启动服务
1
2
3
systemctl reload logstash.service
systemctl restart logstash.service
systemctl enable logstash.service
最后检查
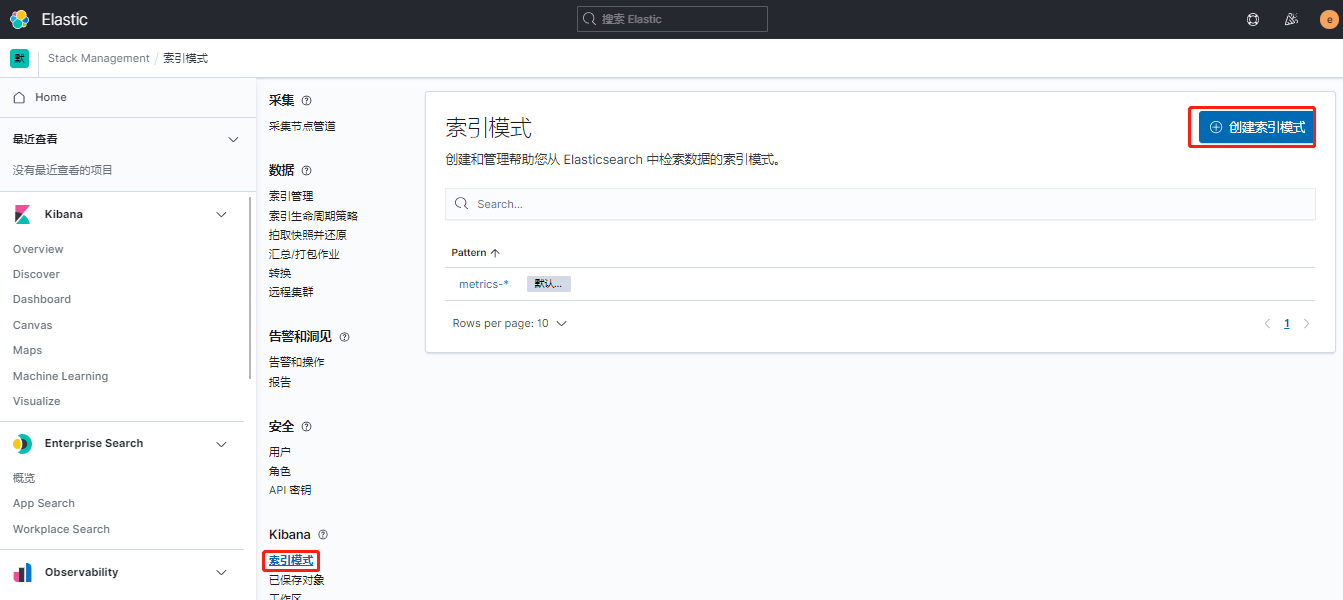
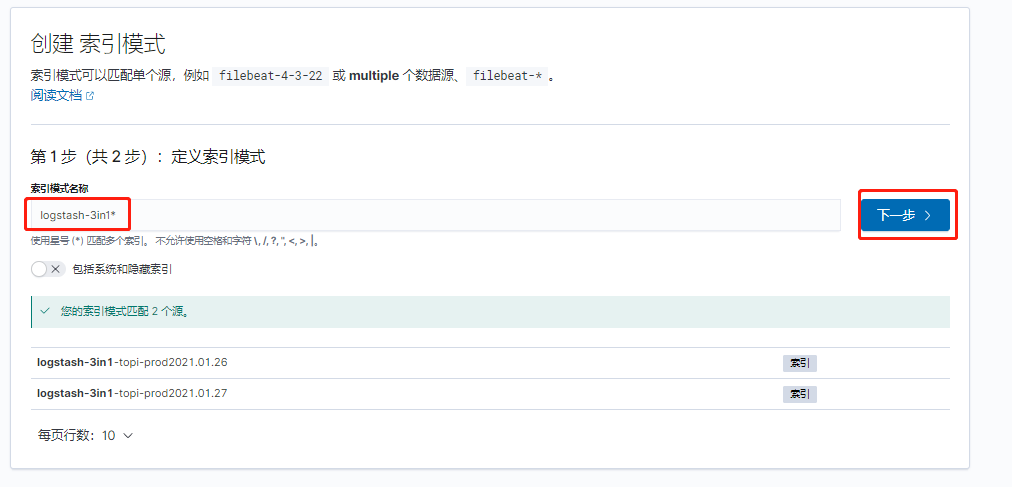
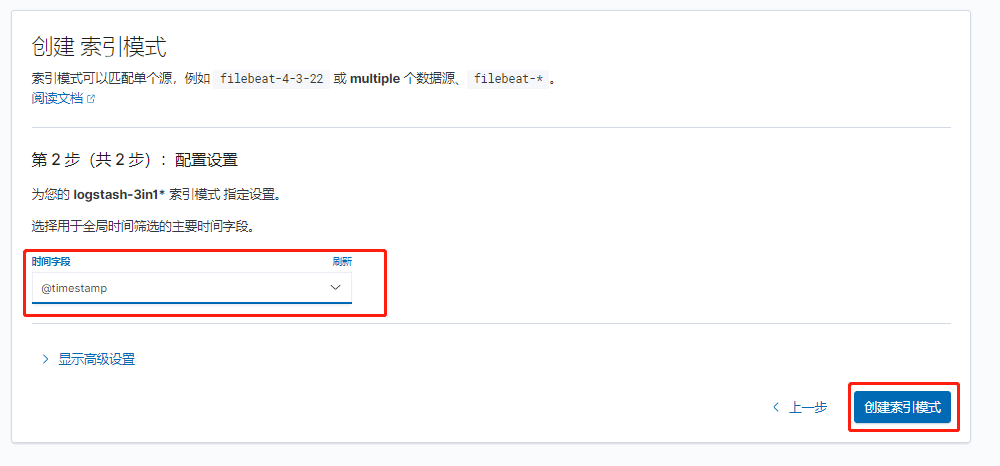
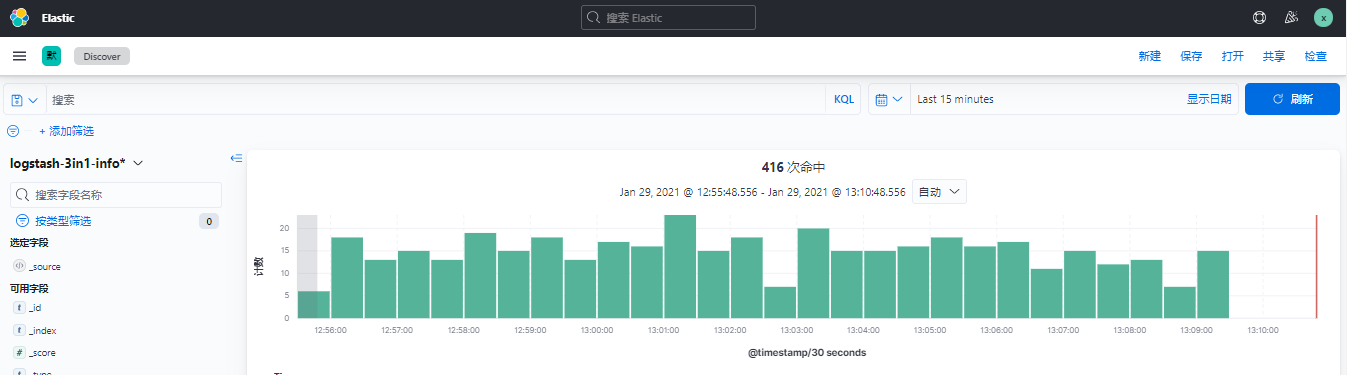
登录kibana创建索引
选择管理–索引模式–创建索引模式索引名称–下一步@timestamp–创建索引模式
文章链接 https://www.cnsre.cn/posts/210325135520/